
50 Mental Models to Think Like a High-Level Generalist - PART 2
50 disciplines. 50 big ideas. 50 mental models. 10 posts. #2

I’ve decided, modestly, to follow in Charlie Munger’s footsteps:
“I’m a big fan of knowing the big ideas in pretty much all the disciplines … and then using those routinely in your judgments. That’s just my system.”
I’ve extracted 50 “big ideas” from 50 disciplines.
5 new ones every week.
You can find the first 5 here.
This week: #6 through #10.
Immunology: Clonal Selection
The Big Idea
Imagine we receive a radio message from an extraterrestrial species: “We’re declaring war. We’re going to wipe your planet out.” How do you prepare?
You don’t know the enemy, their weapons, or their strategy. You’re facing an “infinite” adversary in the sense that the space of possibilities exceeds what you can even imagine.
That’s exactly what your immune system has to do, constantly.
To do that, it pre-positions as much diversity as possible and lets reality do the selecting. This process is called clonal selection:
The immune system maintains a gigantic library of immune cells (especially B cells and T cells), each carrying slightly different receptors.
When a pathogen X shows up, most cells won’t detect it, but a few will partially match it.
That partial match triggers a cascade that makes those cells proliferate and specialize.
Some of the newly produced cells are kept and strengthen immune memory.
Next time a similar pathogen appears, the response is faster and stronger.
In one line: clonal selection = variation → selection → amplification.
Here’s an excellent visual representation of the process:
Ontologically, it’s simply an immune learning process: the immune system learns how to defend itself against a new, unknown “enemy,” and stores what worked.
Interestingly, different types of learning tend to share the same shape, whether it’s human, immune, or machine learning.
The Mental Model
The process is so effective that it almost begs to be translated.
When you’re facing a problem that’s complex, uncertain, or evolving:
Generate variety: produce multiple candidates (hypotheses, options, prototypes, routines, etc.) with low unit cost and fast feedback.
Define a selection criterion: a metric that tells you a solution works “well enough.”
Let reality select: deploy candidates and observe which ones survive by the criterion.
Amplify: double down on what works, while reintroducing a bit of variety.
Store it: treat it as learning, and optimize the learning process itself (immune memory).
Repeat until the solution is good enough, or stop if the cost (time, attention, money) becomes too high.
Simple, but brutally effective.
I joined social media three months ago and knew absolutely nothing about it. Faced with that complexity, I applied exactly the method above:
I opened accounts on a bunch of platforms.
I tried many things in parallel (and still am), then focused on what worked best.
This series is one way for me to inject variability during the amplification phase.
That said, don’t judge the method by my “performance.” Most problems come from the strategist more than the strategy.1
This isn’t gratuitous self-bashing, but if nature selected this learning process for the immune system over millions of years, it’s probably because it’s fundamentally extremely effective.
Machine Learning: Overfitting
The Big Idea
No wise teacher would use the exact test questions as training exercises. Students would have massive incentives to memorize the answers, and the teacher’s hard work would be wasted.
So teachers vary practice problems and test problems. Surprisingly (or not), that’s also what we do in machine learning.
What we really want from a neural network is discriminative power across the widest possible range of cases.
In general, when you train a neural network, you split the data into three sets:
a training set,
a validation set (used during training to tune and decide when to stop, but not essential for our purpose here),
and a test set.
The goal is to prevent the network from becoming “too perfect” on the training set, and then failing on slightly different data (the test set), which would make it useless. That failure mode is overfitting.

There are many ways to reduce overfitting (e.g., dropout, deliberately forcing “forgetting”), but the most fundamental lever is simple: the quality, diversity, and representativeness of your data.
The closer your sample gets to the true population of situations the model will face as input, the less overfitting you should expect (all else equal).
But in machine learning, the overall process is relatively standardized, which makes optimization much easier than in biological learning.
In biological learning:
We don’t have a clean, reliable “test set” metric the way we do in machine learning.
Data arrives discontinuously and in a non-standardized way.
Training is often discontinuous (e.g., learning how to react appropriately when someone wishes you happy birthday: one “training session” per year).
So the consequences of overfitting are more subtle and more pervasive, but we can still borrow a lot from machine learning to reduce its impact.
The Mental Model
Overfitting is a cognitive bias. And like most cognitive biases, its impact tends to shrink simply by becoming aware of it.
Overfitting’s best friend is precision. Your detector should go on high alert whenever something feels too clean, too specific, too perfectly fitted.
A classic example in finance: indicators or models that “predicted” the last 10 bear markets or recessions. They’re almost always built after the fact and tuned to the past, impressive in hindsight, fragile in the future.
Statistically, there’s an infinite supply of indicators. So you can always find some that fit the historical record perfectly. But statistically, (almost) all of those indicators won’t predict the future.
There’s no absolute rule, but these heuristics make the mental model usable in practice:
Precision → Alert. The more precise a claim/model/theory is, the more suspicious you should become.
Stress-test robustness. Automatically ask: does this survive changes in conditions? The more precise it is, the more it must.
Separate discovery from proof. What helped you find the idea should not be what you use to “validate” it (keep training set and test set separate). If you’re using the same data for both, the odds of overfitting jump.
Sometimes: don’t learn. Human unlearning is expensive. When the downside of internalizing a bad model is high, caution can beat cleverness: better to skip learning than to overfit and then pay the price to unlearn.
Anthropology: Thick Description
“There is no reason to believe that beasts have thought… and that it is more probable that they are devoid of it.”
Anyone who has a pet would call the person who said that cold, detached, and irrational.
But your certainty probably wobbles if I tell you that this very same person also pioneered analytic geometry, while being one of the most famous philosophers of all time: René Descartes.
So how can a mind that is clearly brilliant say something that looks this absurd?
As usual, you have to zoom out: think in fields, not points.
The trap is judging an idea (or a behavior) outside its context. In anthropology, we often contrast two levels:
Thin description: you describe the act “as-is,” isolated, stripped of its environment.
Thick description: you describe the act together with the system that gives it meaning (norms, beliefs, tools, era, constraints…).

If you ignore the environment and focus only on the act itself, “irrationality” is often the only conclusion our personal lenses can offer.2
But once you integrate the constraints shaping that environment (knowledge constraints, tools, time, culture, incentives, etc.), many behaviors that looked irrational start to make sense.
Even though the concept comes from intercultural analysis, it applies extremely well to “everyday life”:
Why did this person commit such an obvious fraud?
Why buy this stock?
Why sign this treaty?
If you stop explaining the world with “irrationality,” and instead look for the context and constraints that structured the decision, you very often get closer to the truth.
The Mental Model
Whenever a behavior (decision, statement, action, etc.) feels irrational, pause judgment long enough to answer six questions:
What is the real goal of this behavior?
Are there credible alternatives to reach that goal?
If yes, which ones, and what do they cost?
What does the actor risk (reputation, sanction, loss of face, etc.)?
What does the actor actually know, and what might they not know?
Am I sure I know all the important constraints that could be shaping this behavior?
Applied to the biggest financial crises in history, constraints usually explain far more than “pure irrationality”: liquidity constraints, leverage constraints, balance-sheet constraints, and so on.
And the biggest bull runs are often tied to the gradual, continuous relaxation of those constraints. Irrationality tends to matter most in the final act.
Information Theory I: Overconsumption of Complexity
The Big Idea
Promise made, promise kept.
Nothing is more fundamental than information. In some sense, any phenomenon can be modeled as a flow of bits:
the erosion of your neighbor’s home’s walls,
your neighbor’s cells in the middle of mitosis,
the evaporation of the black hole at the center of our neighboring Andromeda galaxy.3
Nothing escapes that lens (yes, even the neighbors).

This is perfect, because the whole point of this series is to extract important ideas and generalize them to maximize their usefulness (and that’s why at least one more information-theory concept will show up later in the series).
But not all information is created equal.
In information theory, information is tightly linked to uncertainty: the core quantity (entropy) measures uncertainty, and “information gained” can be seen as uncertainty reduced.
If it doesn’t reduce the relevant uncertainty, whether it’s true, rare, or interesting is trivial.
So in practice, a piece of information has value only if it reduces the uncertainty that actually matters (i.e., the uncertainty that blocks a decision).
Ignoring this leads to the error of overconsuming complexity: hoarding non-decisive information while feeling like you’re doing rigorous work.
The fix is to focus on the marginal value of new information.
The Mental Model
We’re almost constantly foraging for information (visual, auditory, procedural, etc.).
So the process needs to be fast, cheap, discriminating, and repeatable:
Decision variable: State the decision type (act, wait, choose, quit, etc.).
Switching information: What single piece of info could drastically flip my decision?
(e.g., “I turn down this job offer if I find a negative, non-anonymous review from a former employee.”)Compression: If no decisive info comes to mind quickly, compress the problem into 2-3 variables.
Stopping rule: Set an exit rule in advance (e.g., “I stop after 30 minutes, no matter what”).
Marginal value test: For each new piece of info: does it reduce uncertainty on those variables enough to change the decision?
Exit: Stop when either:
a decision is made + you can name the information that changed your mind, or
your stopping rule triggers.
Across a lifetime, the marginal value of this reflex is enormous. It even makes you wonder why information theory isn’t taught in school in a practical (math-free way), through heuristics like these.
Motivation Psychology: The Expectancy-Value Trick
The Big Idea
Motivation psychology is a deep well of knowledge you can apply to everyday life.
I could have talked about feedback types and what they’re good for, about juggling extrinsic vs. intrinsic motivation, about emotion as a signal of motivation rather than the enemy, etc. But I chose a “simple equation” of motivation:
Motivation ≈ Goal value × Perceived probability of success4
Be kind to motivation psychologists. The field has roots in 19th-century physiology, where there was a strong urge to describe human body with equations, and that habit stuck around well into the 20th century.
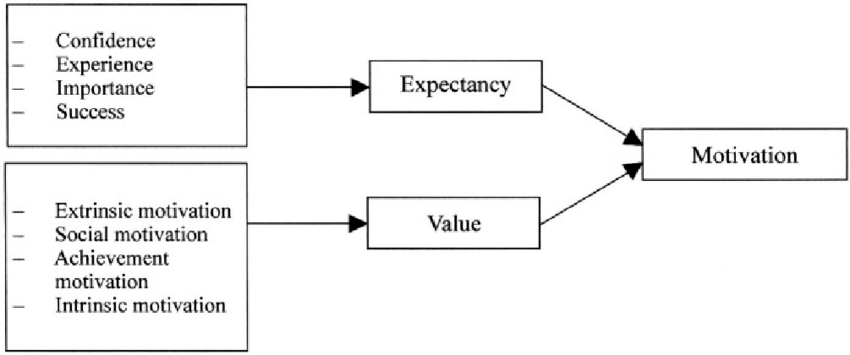
Even if this equation doesn’t make mathematical sense, what matters are the concepts and the relationship between them:
Your motivation for a task depends on the value of the goal and your perceived odds of succeeding.
These are tendencies, not absolute rules. But often very pronounced:
High value + low probability → anxiety + avoidance
High value + high probability → motivated
Low value + high probability → apathy, procrastination, etc.
Low value + low probability → indifference
But that’s not all. There’s a crucial nuance that turns this into something actionable.
The Mental Model
I said value and perceived probability. So we’re talking about perception (as always, with living things).
The upside is that we can influence our perceptions.
Concretely, if you want to keep motivation high for longer, you have two levers (the examples may sound caricatured, but this is about perception; use whatever fits you best):
Increase perceived value
Add meaning to the task → “My kids’ air quality will be better if I sort my waste properly.”
Tie it to identity5 → “I’m someone who takes care of myself, so I’m doing this workout.”
Strategic rewards/punishments → “I won’t look like someone who breaks their word if I finish this post by Sunday.” (Notice: it’s a negative reward, I’m avoiding a punishment.)
Increase perceived probability of success:
Reduce task difficulty → go from a 1-hour run to 45 minutes
Reduce perceived difficulty by clarifying the next step → “analyze management’s track record” rather than “do my research”
Design the task to provide fast evidence of progress → break a complex task into a sequence of simpler sub-tasks with feedback.
Actively managing, and even “editing”, our perceptions is (probably) the biggest cheat codes in psychology.
This mental model is just one example among many.
10/50. 40 to go. I’m almost starting to feel nostalgic.
As much as I genuinely enjoy working on this project, the main goal is still for these tools to reach as many people as they can actually help.
So if you think this post could be useful to someone else, share it.
This project is 100% free, and it will stay that way.
Take care,
Masters of Compounding
Sources
1. Immunology: Clonal Selection
As is often the case, it’s hard to point to a single truly “foundational” study behind a theory. More often, knowledge accumulates until a few people (or sometimes a single person) come along and formalize it into a coherent whole. That’s exactly what this book does. Maybe it’s because the field was much less developed at the time, but the book is very readable if you still have a solid memory of your biology classes: Frank Macfarlane Burnet (1959). The Clonal Selection Theory of Acquired Immunity. Vanderbilt University Press.
For a more recent (and more comprehensive) approach to the topic: Hodgkin, P. D. (2008). “The golden anniversary of Burnet’s clonal selection theory.” Immunology and Cell Biology, 86(1), 15.
2. Machine Learning: Overfitting
For a simple introduction to overfitting vs. underfitting and the evergreen bias–variance tradeoff: Google. Machine Learning Crash Course — “Datasets, Generalization, and Overfitting” (Overfitting / Generalization module). Google for Developers, last updated December 3, 2025.
This paper is “old” by machine-learning standards, but it nails the core point: generalization is the real problem. And it’s exactly this kind of (sometimes uncomfortable) thinking that, in my view, enabled the field’s major breakthroughs, up to modern architectures like transformers: Zhang, C., Bengio, S., Hardt, M., Recht, B., & Vinyals, O. (2016). Understanding deep learning requires rethinking generalization.
3. Anthropology: The Thick Description
The foundational text for the concept. The book is fairly old and you can feel it at times, but it’s still a worthwhile read: Clifford Geertz (1973). “Thick Description: Toward an Interpretive Theory of Culture”, in The Interpretation of Cultures.
For a more recent critique of the concept and its limits: Susen, S. (2024). The Interpretation of Cultures: Geertz Is Still in Town. Sociologica.
4. Information Theory I: Overconsumption of Complexity
The foundational text of information theory, and one of the greatest papers of all time. It’s fairly hard to read without math skills (even if it’s not very demanding), but the first 10 pages are really worth it, IMO. Claude Shannon (1948). A Mathematical Theory of Communication.
For a detailed framework explaining why humans tend to over-consume information (and how they implicitly trade off value vs. cost when searching, reading, and “digging”): Peter Pirolli & Stuart Card (1999). Information Foraging. Psychological Review.
5. Motivation Psychology: The Expectancy-Value Trick
The model described in this post is Expectancy-Value Theory. It’s neither the most comprehensive nor the dominant model today. But most modern frameworks can be seen as more developed versions of this core idea. For a deep dive into the foundations: Wigfield, A., & Eccles, J. S. (2000). Expectancy–Value Theory of Achievement Motivation. Contemporary Educational Psychology, 25(1), 68–81.
For a broader view of the current state of motivation psychology: Urhahne, D., & Wijnia, L. (2023). Theories of Motivation in Education: an Integrative Framework. Educational Psychology Review, 35, Article 45.
DISCLAIMER:
I’m not a domain expert in every field I’m drawing from. I’m simply an investor with a lot of curiosity, and a lot of time to feed it. If you spot an empirical error or want to add nuance, I’d welcome corrections, my goal is accuracy and usefulness.
If you’re an expert in any domain, WHATEVER IT IS, and you have a “big idea” that generalizes well, please don’t hesitate to suggest it. Drop it in the comments, DM me, or write a note and tag me, I’d genuinely love to include it. Of course, I’ll credit you in the post.
I don’t feel like I understand it much better now, but at least I’m having a lot of fun.
This is extremely analogous to the fundamental attribution error in social psychology: our general tendency to over-attribute other people’s behavior to internal causes and underestimate the situation. The anthropological framing feels more global and more generalizable to me, which is why I’m leaving the social-psych angle aside here.
For the neighboring galaxy, I should’ve used the Large Magellanic Cloud, which is much closer. But there still isn’t solid enough evidence that it hosts a black hole. Some data collected in 2025 does suggest it might, but rigor first.
More recent models add impulsiveness (how distractible you are while taking action) and delay (how far away the deadline is) as variables. Their predictive value is real, but I chose to leave them out. The incremental benefit didn’t feel worth the added complexity in this mental model.
Actively managing our identity is too important not to add to the list of 50 mental models.
This is becoming my Sunday night read in bed. Particularly gelled with clonal expansion and motivation psychology. Two thoughts I had - do you think the immune system would recognise something entirely alien (ie non Earth-biological)? Or does clonal expansion (and extensions of that thinking beyond biology) require an infinite panel against a known pattern of information (peptides/sugars/other biomolecules)? In which case maybe that layer needs to be added to that style of thinking - diversity and variation within a fixed field of possibility.
Motivation psychology was interesting. I tend to motivate with negative rewards and hadn't really thought about it before. Maybe time for a change!
The breadth and depth of this series are truly remarkable. It’s rare to find a resource that doesn't just list mental models, but meticulously explains how to synthesize disparate concepts from physics, biology, and social sciences into a cohesive framework for real-life decision-making. I reserve this series for slow, deliberate reading.
Seeing how these models translate into sharper investing insights is a masterclass in 'latticework' thinking. Your series is becoming an essential curriculum for anyone serious about compounding their intellectual capital. Brilliant work!